RE:用匹配来演绎编程的艺术
学习一时爽,一直学习一直爽
Hello,大家好,我是 Connor,一个从无到有的技术小白。上一次我们说到了 pyquery 今天我们将迎来我们数据匹配部分的最后一位重量级人物,也是编程语言中普及率最高的一个东西,它就是正则。正则长期以来占据着编程新手的禁忌之地,大家对它是又爱又恨。今天,我们将揭开他神秘的面纱,直面正则,并助你征服它,让它成为你的得力助手!

1. 正则的介绍
由于正则并不是 Python 所独有的内容,本文大部分会以正则的角度来进行描述和讲解,而不局限于 re 库,文章会穿插以 re 为例,对正则的例子进行讲解。
1.1 正则的起源
想要彻底掌握正则,就要从头到尾的了解它。那么正则是如何诞生的呢?这要追溯到上世纪人们对人类神经系统如何工作的早期研究。两位神经生理学家研究出一种数学方式来描述这些神经网络。具体叫什么我就不说了。

1956 年, 一位数学家在上面两位神经生理学家早期工作的基础上,发表了一篇标题为“神经网事件的表示法”的论文,引入了正则表达式的概念。正则表达式就是用来描述他称为“正则集的代数”的表达式,因此采用“正则表达式”这个术语。
随后他们发现可以将这一研究成果广泛的应用于其它领域的研究。Ken Thompson 使用它来进行一些早期的计算搜索算法的一些研究,Ken Thompson 是 Unix 的主要发明人。正则表达式的第一个实用应用程序就是 Unix 中的 qed 编辑器。
然后,正则表达式在各种计算机语言或各种应用领域得到了广大的应用和发展,演变成为目前计算机技术森林中的一只形神美丽且声音动听的百灵鸟。到目前正则表达式在基于文本的编辑器和搜索工具中依然占据这一个非常重要的地位。
在最近的六十年中,正则表达式逐渐从模糊而深奥的数学概念,发展成为在计算机各类工具和软件包应用中的主要功能。不仅仅众多UNIX工具支持正则表达式,近二十年来,在 Windows 的阵营下,正则表达式的思想和应用在大部分 Windows 开发者工具包中得到支持和嵌入应用!
Windows 系列产品对正则表达式的支持发展到无与伦比的高度,目前几乎所有 Microsoft 开发者和所有.NET语言都可以使用正则表达式。包括 Python、Java、JavaScript、Go 等非 Windows 系列的产品也对正则进行了支持,这无疑将正则变成了编程界的宠儿,可以说得正则者得天下!
所以,看到这里是不是想要迫不及待地来学会正则了???让我们一起来看看正则的概念:
1.2 正则的概念
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
Emmn… 看了这么官方的描述还是有些懵逼,说白了正则表达式就是通过一些指定好的特殊字符来代替某种字符。举个例子:大家小时候都玩过扑克游戏排火车,就是当你现在排的牌和前面的任意一张大小相同的时候,无论中间有多少,有什么牌你都可以获取这中间所有的牌。正则和这个类似,无视中间所有的东西,只要满足你这个规则,就可以取出中间所有的内容!
不知道我的例子够不够清晰,反正我绞尽脑汁也只想到了这一个比较像的例子,如果你有什么更好的例子,可以留言或评论,我将引用你的例子。
说完了正则的概念,我们再来看看正则有哪些特点吧!
1.3 正则的特点
正则表达式有如下的特点:
- 灵活性、逻辑性和功能性非常的强;
- 可以迅速地用极简单的方式达到字符串的复杂控制。
- 适用于任何字符串
2. 正则表达式的基础知识
这里往后都是基础的东西,如果你觉得你都懂了想直接看Python的re库请
既然大概了解了正则的历史以及他的功能和特点,那么让我们从正则表达式的基础知识来开始学习吧。大多数教程都是从元字符开始的,但是他们忽略了一些最基础的东西,这些东西对于初级运用或许没有任何关系,但是当你要使用到高级用法的时候很可能会造成混乱,甚至是遗忘,所以我们在开始前先来说一说正则的基础知识:
2.1 字符串的位置讲解
在我们的印象中,光标的位置就是在字符之后的,但是实际上在底层,光标指的并不是当前字符的位置,而是光标前面的这个位置,如图:
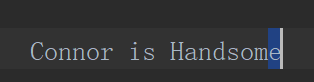
真实的光标位置指的是光标之前的这个字母,是这个字母 e 的位置,所以在一个长度为 n 的字符串中,总共有 n + 1 个位置。例如:
(0)a(1)b(2)c(3)
在这个长度为 3 的字符串 abc 中,一共有 (0)(1)(2)(3)四个位置
2.2 占有字符和零宽度
可能现在说占有字符和零宽度会让你感觉有些不知所措,但是当你看完后面的内之后再反过来看占有字符和零宽度的时候你就会恍然大悟,将这两个概念了然于心了。
正则表达式匹配过程中,如果子表达式匹配到东西,而并非是一个位置,并最终保存到匹配的结果当中。这样的就称为占有字符,而只匹配一个位置,或者是匹配的内容并不保存到匹配结果中,这种就称作零宽度,占有字符是互斥的,零宽度是非互斥的。也就是一个字符,同一时间只能由一个子表达式匹配,而一个位置,却可以同时由多个零宽度的子表达式匹配。
2.3 正则表达式的控制权与传动
正则表达式由左到右依次进行匹配,通常情况下是由一个表达式取得控制权,从字符串的的某个位置进行匹配,一个子表达式开始尝试匹配的位置,是从前一个匹配成功的结束位置开始的。
3. 正则表达式的语法
3.1 正则表达式的元字符
正则表达式的元字符是正则表达式的根本,所有的正则表达式都有元字符组成,正则表达式的元字符包括下列几种:
3.1.1 基本元字符
| 字符 | 描述 | |
|---|---|---|
| . | 匹配除换行符外的任意字符 | |
| * | 匹配0个或多个符合表达式的字符 | |
| ? | 匹配0个或1个符合表达式的字符 | |
| + | 匹配1个或多个符合表达式的字符 | |
| […] | 匹配方括号内的任意字符 | |
| [^…] | 匹配除方括号字符内的任意字符 |
3.1.2 转义元字符
| 字符 | 描述 |
|---|---|
| \ | 用于转义下一个字符 |
| \A | 仅匹配字符串的开头 |
| \b | 匹配一个单词的边界 |
| \B | 匹配非单词边界 |
| \cX | 匹配指明的控制字符 |
| \d | 匹配一个数字,等价于[0-9] |
| \D | 匹配一个非数字,等价于[^0-9] |
| \f | 匹配一个换页符,等价于\x0c和\cL |
| \n | 匹配一个换行符,等价于\x0a和\cJ |
| \t | 匹配一个制表符,等价于\x09和\cI |
| \r | 匹配一个回车符,等价于\x0d和\cM |
| \s | 匹配 一个不可见的字符 |
| \S | 匹配一个可见的字符 |
| \v | 匹配一个垂直制表符,等价于\x0b和\cK |
| \w | 匹配包括下划线的任何单词字符 |
| \W | 匹配任何非单词字符 |
| \Z | 仅匹配字符串的末尾 |
| \xn | 匹配转移为\xn的十六进制转义字符 |
| \un | 匹配一个Unicode转义字符 |
3.1.3 限定类元字符
| 字符 | 描述 |
|---|---|
| {n} | 匹配确定的n个字符 |
| {n,} | 匹配至少n个字符 |
| {n,m} | 匹配至少n个字符,至多m个字符 |
| | | 或符号,用于连接多个表达式 |
| - | 范围符,只能用于方括号中,如[a-z] |
| ^ | 匹配字符串的开头,在方括号中表示取反 |
| $ | 匹配字符串的末尾 |
| (parameter) | 将括号内的内容进行匹配并分组 |
| (?!parameter) | 正向否定预查,匹配不是parameter的内容 |
| (?=parameter) | 正向肯定预查,匹配是parameter的内容 |
| (?:parameter) | 匹配parameter获取匹配结果 |
| (?<=parameter) | 反向肯定预查,在任何匹配的paraemter处开始匹配字符串 |
| (?<!parameter) | 反向否定预查,在任何不符合parameter的地方开始匹配字符串 |
只是在这里向你罗列元字符你是不会懂如何使用正则的,请稍安勿躁,稍后我们将以 Python 中的正则为例,为大家逐一展示各种元字符的用法。如果你比较急切,请点击这里来快速查看 re 库的使用方法。了解了元字符,我们再来认识一下可打印字符与非打印字符:
3.2 打印字符与非打印字符
3.2.1 打印字符
如你所见,你在网上浏览到的所有的字符,这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。这些全部可见的字符都叫做可打印字符
3.2.2 非打印字符
非打印字符也可以是正则表达式的组成部分。下表列出了表示非打印字符的转义序列:
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^\f\n\r\t\v ]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
打印字符和非打印字符非常易懂,没什么难点,一笔带过,下面我们来看看运算符的优先级:
3.3 正则表达式运算符的优先级
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。相同优先级的从左到右进行运算,不同优先级的运算先高后低。下表从最高到最低说明了各种正则表达式运算符的优先级顺序:
| 运算符 | 描述 |
|---|---|
| \ | 转义符 |
| (), (?: ), (?=), [] | 圆括号和方括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| | | 替换,"或"操作字符 |
运算优先级非常类似于四则运算,没什么好说的,下面我们来看看正则的匹配模式:
3.4 正则的匹配模式(表达式修饰符)
正则表达式有时候不只是需要使用简单的正则语句,有时候还需要挑选合适的匹配模式(表达式修饰符),通过这些不同的匹配模式,可以提升匹配的效率。正则的匹配模式如表:
| 模式 | 描述 |
|---|---|
| /a | 强制从字符串头开头进行匹配 |
| /i | 不区分大小写匹配 |
| /g | 全局匹配 |
| /m | 多行匹配 |
| /s | 特殊字符匹配 |
| /u | 不重复匹配 |
| /x | 忽略模式中的空白 |
到这里就介绍完元字符了,如果你想直接看元字符的使用示例,请
4. Python 的正则库 – re库
正则被广大编程语言所支持,Python也不例外,Python 官方为我们封装了 re 库来支持正则的使用,下面我们一起来走进 Python 的 正则库–re库:
4.1 Python 中的正则匹配模式
Python 的正则也是正则,所以它也有匹配模式。但这匹配模式又有些不同于正则的表达方式,我们来看一看:
| 修饰符 | 描述 |
|---|---|
| re.A | 强制从字符串头开始匹配 |
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符 |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
可以看到,匹配模式并不再是 /* 来进行表示了,而是变成了 re.* 来进行表示了。
4.2 Python 中的正则常用方法
Python 既然是一种语言,那么它定然不会让我们傻敷敷的去使用,Python 为我们封装好了方法,我们来逐一看一下都有哪些方法吧:
4.2.1 compile()
re.compile(pattern, flags=0)
这个方法用来将正则表达式进行编译,返回一个Pattern对象。这么说你一定还是很懵逼,我们来举个例子:
import restring = "Learning makes a good man better and ill man worse."pattern = re.compile(r"m\w+")result = pattern.findall(string)print(result)
返回结果:
['makes', 'man', 'man']
这样就显而易见了,先将正则表达式进行编译,在下次使用的时候直接给编译好的正则表达式一个字符串让它去匹配就好了。这样做的好处是提高了性能,如果你要处理大文档,建议你这样使用。
4.2.2 escape()
escape(pattern)
这个方法可以用来匹配除 ASCII字符,数字和特殊字符 ‘_’ 以外的所有字符。官方的说法就是不一样,这个东西有时候真的挺让人懵逼的,简单来说,这个方法就是用来消除字符串中的任何特殊字符效果的。
我举个例子你就明白了。有时候问哦们在匹配网址的时候,因为 ‘.’ 是特殊字符,所以有些时候我们无法成功的进行匹配,我们需要转义后再进行匹配,大部分人的操作是这样的:
import restring = "www.baidu.com"result = re.findall(r"baidu\.com", string)print(result)
这样做确实可以达到我们想要的效果,但是对于想要玩骚操作的我们来说,这样太 Low 了,所以就有了这样的方式:
import restring = "www.biadu.com"result = re.findall(re.escape("baidu.com"), string)print(result) 这样一来,我们就省去了写转义的麻烦步骤,案例中需要转移的内容较少,可能看不出有什么优势,但是当你匹配大量需要转移的内容的时候,这样做不仅可以省去打转义字符的麻烦,而且也防止我们漏打,错打转义字符。
当然,你也要注意一点,使用这个方法会消除一切特殊字符的特殊效果,使用这种方法匹配具有一定的局限性,不能再进行模糊匹配了,请按需使用。
4.2.3 findall()
findall(pattern,string,flags = 0)
通过这个方法匹配出来的是字符串中所有非重叠匹配的列表。老规矩,举个例子:
import restring = "Learning makes a good man better and ill man worse."result = re.findall(r'm\w+', string)print(result)
运行结果:
['makes', 'man', 'man']
4.2.4 finditer()
finditer(pattern, string, flags=0)
通过这个方法可以将字符串中所有非重叠匹配上返回迭代器。对于每个匹配,迭代器返回一个匹配对象,匹配结果中包含有空对象。
简单的说,就是返回一个可迭代的 Objct 对象,这是它和 findall() 方法唯一的区别。 我们举个例子:
import restring = """ QQ邮箱: 123456789@qq.com 网易邮箱: 123456789@163.com 126邮箱: 123456789@126.com"""ls = re.finditer(r"(\d+@\w+.com)", string, re.S)print(type(ls))for item in ls: print(item.group())
运行结果如下:
123456789@qq.com123456789@163.com123456789@126.com
生成的可迭代的 Object 对象中,内部对象都为 SRE_Match 对象,该对象不可直接提取匹配的内容,需要通过 group() 方法来进行提取。
4.2.5 fullmatch()
fullmatch(pattern, string, flags=0)
通过这个方法可以用来判断整个字符串是否匹配规则,如果符合规则则返回 match object。不符合则返回 None。举个例子:
import restring = """QQ邮箱: 123456789@qq.com"""ls = re.fullmatch(r"QQ邮箱: 123456789@qq.com", string, re.S)print(ls.group())
运行结果如下:
QQ邮箱: 123456789@qq.com
如果我们随意改变一下规则:
import restring = """QQ邮箱: 123456789@qq.com"""ls = re.fullmatch(r"QQ邮箱", string, re.S)print(ls)
运行结果:
None
可以看得出,只有当整个字符串都符合匹配规则的时候才能匹配到东西,否则的话返回的是 None。
4.2.6 match()
match(pattern, string, flags=0)
使用这个方法可以尝试在字符串的开头进行匹配,返回匹配对象,如果未找到匹配,则返回None。
你应该注意到了,它是在字符串的开头进行匹配的,如果你还是不太清楚,那我们接着来看例子:
import restring = """QQ邮箱:123456789@qq.com"""ls = re.match(r"QQ邮箱", string, re.S)print(ls)
运行结果如下:
<_sre.SRE_Match object; span=(0, 4), match='QQ邮箱'>
因为我们匹配的法则在开头有,如果我们换个规则的话:
import restring = """QQ邮箱:123456789@qq.com"""ls = re.match(r"\d+", string, re.S)print(ls)
运行结果:
None
按照我们的想法它应该会匹配到@前面的一串数字吧?但是实际上它并没有匹配到。这就是所谓的在字符串的开头进行匹配。
4.2.7 purge()
通过这个方法可以清除正则表达式的缓存。这个方法貌似没有啥好说的 …

4.2.8 search()
search(pattern, string, flags=0)
搜索整个字符串以匹配符合规则的字符串,如果有则返回匹配对象,如果没有则返回None。前面说的 match() 方法是只在头部进行匹配,而 search() 方法可以在字符串中的任意位置进行匹配。例如:
import restring = """QQ邮箱:123456789@qq.com"""ls = re.search(r"\d+", string, re.S)print(ls)
运行结果如下:
<_sre.SRE_Match object; span=(5, 14), match='123456789'>
可以看的出,没有在字符串首部的字符也被匹配出来了。相比 match() 方法,search() 方法,findall() 方法要用的更多些。
4.2.9 split()
split(pattern,string,maxsplit = 0,flags = 0)
看到这个方法我想大家第一时间想到的是字符串中的 split() 方法,恭喜你,猜对了,这个方法和 字符串中自带的 split() 方法大同小异,这个方法增加的功能是可以通过正则表达式来进行分割。例如:
首先举一个都能理解的功能:
import restring = """abc,123456789,@qq.com"""ls = re.split(r",", string)print(ls)
运行结果:
['abc', '123456789', '@qq.com']
可以看得出,现在的分割方法和 字符串中自带的 split() 方法没有什么区别。下面我们再看多出来的用法:
import restring = """abc123456789@qq.com"""ls = re.split(r"\d+", string)print(ls)
运行结果:
['abc', '@qq.com']
可以看得出,该方法将 数字作为分割依据进行了分割。如果你足够细心的话,你会发现这个方法还有一个参数,叫 maxsplit 这个方法代表着最大分割次数。比如:
import restring = """abc,123456789,@qq.com"""ls = re.split(r",", string, 1)print(ls)
运行结果如下:
['abc', '123456789,@qq.com']
可以看到它只进行了一次分割,maxsplit 就是用来控制分割次数的,分割从左到右依次进行分割。分割 maxsplit 次。
4.2.10 sub()
sub(pattern,repl,string,count = 0,flags = 0)
将所有符合规则的字符串替换成 repl。最多替换 count个,默认全部替换。这是我个人认为正则中除了 findall() 方法外最有用的方法了。批量替换超级有用!!!

咳咳,激动了啊,下面我们来说说这个方法的使用:
import restring = """abc123456789@qq.com"""ls = re.sub(r"456", "abc", string)print(ls)
运行结果如下:
abc123abc789@qq.com
一下就把字符串中的 456 给替换成 abc了,贼带劲。用了这个方法你还想用 replace方法吗?那个方法多傻,如果你不觉得,一会我会让你认同我的观点的。我们先往下说,sub() 方法也有一个计数参数 count,我们可以通过给它赋值来指定替换个数。比如:
import restring = """abc12abc67abc@qq.com"""ls = re.sub(r"abc", "---", string, 2)print(ls)
运行结果:
---12---67abc@qq.com
在上面的程序中我们指定了替换个数2,所以结果中只替换了两个 abc,并没有全部替换。如果不指定 count 参数的话,默认会进行全部替换。
4.2.11 subn()
subn(pattern,repl,string,count = 0,flags = 0)
这个方法和 sub() 方法没有什么本质上的区别,唯一的不同就是它返回的是一个元组,这个元组包含有两个内容,(1)替换后的字符串,(2)整个字符串中的替换次数。举个例子:
import restring = """abc12abc67abc@qq.com"""ls = re.subn(r"abc", "---", string)print(ls)
运行结果如下:
('---12---67---@qq.com', 3) 4.2.12 template()
template(pattern, flags=0)
这个方法我查了很多资料,国内的网站并没有几个人写这个方法的,可能有写的,但是没有用这个标题来进行发表吧,总之我没有找到什么详细的资料,但是通过他的官方解释:“编译模板模式,返回模式对象” 可以看得出它返回的是一个模式对象,和 re.compile() 方法类似,返回的都是一个模式对象。应该用法和 re.complie()相似。
但是我查阅了国外的网站,大家有提到说发现这个函数,但是并没有发现有什么用处。大家说,可能这个函数并未实现预期想要的功能,或者这个函数出现了什么问题而关闭了。所以只能暂时停留在这个状态。当然平时我们也用不到这个函数
我通过自己的琢磨,自己的尝试,发现这个函数大部分函数功能是和 compile() 方法相同的。比如:
import reabc = re.template(r"abc", re.I)string = "abcasdfadsfABCasdfabcasdfasdf"result = abc.findall(string)print(result)
运行结果如下:
['abc', 'ABC', 'abc']
但是最主要的问题是,该方法禁用所有的特殊字符,即re的元字符,比如:
import reabc = re.template(r"\d+", re.I)string = "abcasdfadsfABCasdfabcasdfasdf"result = abc.findall(string)print(result)
运行结果如下:
Traceback (most recent call last):File "G:/Python/PyWin/test.py", line 2, inabc = re.template(r"\d+", re.I) ....
这个情况下就直接报错了。所以我想不出来这个函数有什么作用。之所以写出来就当给大家开眼了。如果真的需要使用模板的话,还是建议大家使用 re.compile() 方法来进行操作。
好了,这就是 Python 正则库 re 中的所有函数了。下面我还有几个内容要给大家说
4.3 re 中的 Pattern 对象
这个Pattern 我为什么不在讲方法之前说呢,就是怕你们不明白,让我一下子给弄晕了,所以我选择在讲完所有方法之后再说。这样的话有些人不需要了解这么深,直接找到他们想要的方法,直接去使用就好了。这样也方便他们使用…

好好,我们现在来说 **Pattern **对象。那什么是 Pattern 对象呢?如果你仔细看之前我写的方法的话,你会发现几乎每个正则的方法里都有一个 Pattern 参数 ,回想一下那个参数写的什么? 对,Pattern对象就是我们编译后的正则规则。
之前我们在讲 re.compile() 方法的时候说过,这个方法返回的就是一个 Pattern对象。这个对象几乎可以执行 re 中的所有方法。是比较简单的一个对象。相信大家都可以理解。我觉得也没啥好说的了。

4.4 re 中的 Match 对象
Emmn….说完了 Pattern对象我们现在来说说 Match 对象。

好的好的,我一定好好说这个….这个Match 对象呢,是 re构建的一个对象。我们通过 match(), fullmatch(), search(),fjinditer(),这几种方法返回的都是 Match 对象。我们来看看一个 Match 对象中都包含什么:
<_sre.SRE_Match object; span=(3, 6), match='abc'>
- span 指的是匹配到的字符串在字符串中的位置。例中的 3,6 分别是开始位置和结束位置。
- match 指的是匹配到的内容
下面我们来说说 Match 对象中常用的方法:
| 方法 | 解释 |
|---|---|
| end([group]) | 获取组的结束位置 |
| expand(string) | 将match对象中的字符串替换成指定字符串 |
| group(index) | 某个组匹配的结果 |
| groupdict() | 返回组名作为key,每个分组的匹配结果作为value的字典 |
| groups() | 所有分组的匹配结果,每个分组组成的结果以列表返回 |
| start([group]) | 获取组的开始位置 |
| span([group]) | 获取组的开始和结束位置 |
这就是 Match 对象的所有内容了。还是很容易掌握的嘛。
4.5 re 中的分组使用
说完了 Match 对象,我们自然要说道 正则中的 分组使用。这一部分只是对 Match 对象的补充与强调。我想如果会的人不用我来强调也会明白如何使用的。首先我们来举个例子,分组查找出一些内容:
import restring = "2019-05-01是劳动节"result = re.search(r'(?P\d{4}).(?P \d+)', string)print(result.groups())print(result.group('year'), result.group(1))print(result.group('month'), result.group(2))运行结果:('2019', '05')2019 201905 05
可以看的到,我在分组的时候使用了如下的格式:
(?Ppartten)
在前面我们说了一些关于分组的东西比如说 (?=partten) 、(?:partten)、(?!partten) 等等诸如此类的元字符。但唯独没有说这个。
因为他是 Python中专门的一种格式。<name> 用于给组命名。类似于我们引用库时 as的用法。上面的例子中我们也展示了他的用法。当我们使用某个命名了的租的时候。可以直接使用 group('groupname') 的方法。
这样做的好处显而易见,当我们分了多个组的时候,可以不通过排序来提取内容,直接使用组名更加的简单方便。
5. 正则表达式所有元字符的示例
讲完了正则表达式了,也讲完了python中的 re库,下面我们来将之前说好的元字符的示例逐一展示出来:
5.1 基本元字符的示例
| 字符 | 描述 | |
|---|---|---|
| . | 匹配除换行符外的任意字符 | |
| * | 匹配0个或多个符合表达式的字符 | |
| ? | 匹配0个或1个符合表达式的字符 | |
| + | 匹配1个或多个符合表达式的字符 | |
| […] | 匹配方括号内的任意字符 | |
| [^…] | 匹配除方括号字符内的任意字符 |
元字符 “.” 的示例:
import restring = "abcdefghigklmnopqrstuvwxyz1234567890"result = re.match(r".bc", string)print(result.group())运行结果:abc
元字符 “*” 的示例:
import restring = "abcdefghigklmnopqrstuvwxyz1234567890"result = re.search(r"(a.*g)", string)print(result.group())运行结果:abcdefg
元字符 “?” 的示例:
import restring = "aaabcdefg"result = re.search(r"a?b", string)print(result.group())运行结果:ab
元字符 “+” 的示例:
import restring = "aaabcdefg"result = re.search(r"a+", string)print(result.group())运行结果:aaa
元字符 “[…]” 的示例:
import restring = "aaabcdefg123456789"result = re.findall(r"[\D]+", string)print(result)运行结果:['aaabcdefg']
元字符 “[^...]” 的示例:
import restring = "aaabcdefg123456789"result = re.findall(r"[^\d]+", string)print(result)运行结果:['aaabcdefg']
5.2 转义元字符的示例
| 字符 | 描述 |
|---|---|
| \ | 用于转义下一个字符 |
| \A | 仅匹配字符串的开头 |
| \b | 匹配一个单词的边界 |
| \B | 匹配非单词边界 |
| \cX | 匹配指明的控制字符 |
| \d | 匹配一个数字,等价于[0-9] |
| \D | 匹配一个非数字,等价于0-9 |
| \f | 匹配一个换页符,等价于\x0c和\cL |
| \n | 匹配一个换行符,等价于\x0a和\cJ |
| \t | 匹配一个制表符,等价于\x09和\cI |
| \r | 匹配一个回车符,等价于\x0d和\cM |
| \s | 匹配 一个不可见的字符 |
| \S | 匹配一个可见的字符 |
| \v | 匹配一个垂直制表符,等价于\x0b和\cK |
| \w | 匹配包括下划线的任何单词字符 |
| \W | 匹配任何非单词字符 |
| \Z | 仅匹配字符串的末尾 |
| \xn | 匹配转移为\xn的十六进制转义字符 |
| \un | 匹配一个Unicode转义字符 |
元字符 “\” 的示例:
import restring = "aaabcdefg123456789"result = re.findall(r"\d+", string)print(result)运行结果:['123456789']
元字符 “\A” 的示例
import restring = "aaabcdefg123456789"result = re.findall(r"\A\w", string)print(result)运行结果:['a']
元字符 “\b” 的示例
import restring = "aaabcdefg123456789"result = re.findall(r"\b\w{5}", string)print(result)运行结果:['aaabc'] 元字符 “\B” 的示例
import restring = "I'm the king of the world"result = re.findall(r"\B\w+", string)print(result)运行结果:['he', 'ing', 'f', 'he', 'orld']
元字符 “\d” 的示例
import restring = "abcdefg1234567"result = re.findall(r"\d+", string, re.S)print(result)运行结果:['1234567']
元字符 “\D” 的示例
import restring = "abcdefg1234567"result = re.findall(r"\D+", string, re.S)print(result)运行结果:['abcdefg']
元字符 “\f” 的示例
import restring = "abcdefg\f1234567"result = re.findall(r"\f", string, re.S)print(result)运行结果:['\x0c']
元字符 “\n” 的示例
import restring = "abcdefg\n1234567"result = re.findall(r"\n\d+", string, re.S)print(result)运行结果:['\n1234567']
元字符 “\t” 的示例
import restring = "abcdefg\t1234567"result = re.findall(r"\t", string, re.S)print(result)运行结果:['\t']
元字符 “\r” 的示例
import restring = """abcdefg\r1234567"""print(string)result = re.findall(r"\r", string, re.S)print(result)运行结果:1234567['\r']
元字符 “\s” 的示例
import restring = """abcdefg\n1234567"""result = re.findall(r"\s", string, re.S)print(result)运行结果:['\n']
元字符 “\S” 的示例
import restring = """abcdefg\n1234567"""result = re.findall(r"\S+", string, re.S)print(result)运行结果:['abcdefg', '1234567']
元字符 “\w” 的示例
import restring = """I_m the king of the world"""result = re.findall(r"\w+", string, re.S)print(result)运行结果:['I_m', 'the', 'king', 'of', 'the', 'world']
元字符 “\W” 的示例
import restring = """I'm the king of the world"""result = re.findall(r"\W+", string, re.S)print(result)运行结果:["'", ' ', ' ', ' ', ' ', ' ']
元字符 “\Z” 的示例
import restring = """uvwxyz"""result = re.findall(r"\w{2}\Z", string, re.S)print(result)运行结果:['yz'] 元字符 “\xn” 的示例
import restring = """uvwxyz"""result = re.findall(r"\x77", string, re.S)print(result)运行结果:['w']
元字符 “\un” 的示例
import restring = """uvwxyz"""result = re.findall(r"\u0077", string, re.S)print(result)运行结果:['w']
5.3 限定类元字符的示例
| 字符 | 描述 |
|---|---|
| {n} | 匹配确定的n个字符 |
| {n,} | 匹配至少n个字符 |
| {n,m} | 匹配至少n个字符,至多m个字符 |
| | | 或符号,用于连接多个表达式 |
| - | 范围符,只能用于方括号中,如[a-z] |
| ^ | 匹配字符串的开头,在方括号中表示取反 |
| $ | 匹配字符串的末尾 |
| (parameter) | 将括号内的内容进行匹配并分组 |
| (?!parameter) | 正向否定预查,匹配不是parameter的内容 |
| (?=parameter) | 正向肯定预查,匹配是parameter的内容 |
| (?:parameter) | 匹配parameter获取匹配结果 |
| (?<=parameter) | 反向肯定预查,在任何匹配的paraemter处开始匹配字符串 |
| (?<!parameter) | 反向否定预查,在任何不符合parameter的地方开始匹配字符串 |
元字符 “{n}” 的示例
import restring = """uvwxyz"""result = re.findall(r"u\w{2}", string, re.S)print(result)运行结果:['uvw'] 元字符 “{n,}” 的示例
import restring = """uvwxyz"""result = re.findall(r"u\w{3,}", string, re.S)print(result)运行结果:['uvwxyz'] 元字符 “{n,m}” 的示例
import restring = """uvwxyz"""result = re.findall(r"u\w{1,3}", string, re.S)print(result)运行结果:['uvwx'] 元字符 “|” 的示例
import restring = """uvwxyz"""result = re.findall(r"u\w|x\w", string, re.S)print(result)运行结果:['uv', 'xy']
元字符 “-” 的示例
import restring = """uvwxyz"""result = re.findall(r"[a-z]+", string, re.S)print(result)运行结果:['uvwxyz']
元字符 “^” 的示例
import restring = """uvwxyz"""result = re.findall(r"[^1-9]+", string, re.S)print(result)运行结果:['uvwxyz']
元字符 “$” 的示例
import restring = """uvwxyz"""result = re.findall(r"\w{3}$", string, re.S)print(result)运行结果:['xyz'] 元字符 “(parameter)” 的示例
import restring = """uvwxyz"""result = re.findall(r"u(\w{2})x(\w{2})", string, re.S)print(result)运行结果:[('vw', 'yz')] 元字符 “(?=parameter)” 的示例
import restring = """COD4 COD6 COD8"""result = re.findall(r"COD.(?=4)", string, re.S) #匹配.=4的字符串CODprint(result)运行结果:['COD4']
元字符 “(?!parameter)” 的示例
import restring = """COD4 COD6 COD8 """result = re.findall(r"COD.(?!4)", string, re.S) # 匹配 .!=4的字符串print(result)运行结果:['COD6', 'COD8']
元字符 “(?:parameter)” 的示例
import restring = """COD4COD6COD8"""result = re.findall(r".*?(?:4)", string, re.S) # 匹配获取参数为4的字符串print(result)运行结果:['COD4']
元字符 “(?<=parameter)” 的示例
import restring = """COD4 COD6 COD8 """result = re.findall(r"COD.(?<=4)", string, re.S) # 从右向左匹配.=4的字符串print(result)运行结果:['COD4']
元字符 “(?<!parameter)” 的示例
import restring = """COD4 COD6 COD8 """result = re.findall(r"COD.(?
到这里我们就把正则的所有元字符的示例就都演示完了。我所演示的是最基础的用法,如果真的想要使用高级的用法,还是要自己多进行尝试,多练习。练习的多了使用正则才会信手拈来。
下期预告
你看你说了这么多,又是访问网页,又是获取数据的,说了半天我们还是不知道怎么用。我会只是单独的给你们说这么简单吗?当然会有练习的啦。敬请期待下一期:Python 爬虫十六式 - 第八式:实例解析-全书网!我们通过全书网来让你一下吸收前面的知识。

好了,这就是今天的内容了,不知道你又学会了多少呢?我是Connor,一个从无到有的技术小白,愿你在前进的道路上坚持不懈!
学习一时爽,一直学习一直爽!